모델은 골랐는데,
데이터가 안 들어온다면
RAG의 진짜 경쟁력은 모델이 아니라 데이터입니다. 수집·정제·청킹·임베딩·벡터DB 적재·품질 모니터링까지 RAG 데이터 파이프라인을 운영합니다.
500+ 기업 도입 · 8년+ 운영 경험 · 수집/정제/적재까지 운영
{ "source": "web crawler · login + dynamic", "documents_collected": 128,430, "deduplicated": 121,902, "chunked": 486,217 ✓, "embedded": 486,217 ✓, "upserted_to": "pgvector" ✓, "quality_checks": "passed", "last_run": "2026-06-12 09:00 KST" }
RAG 데이터 흐름을 한 화면 대시보드에서 운영
수집·정제·청킹·임베딩·벡터DB 적재를 한곳에서
아래 화면은 샘플 예시 대시보드입니다. 실제 출시된 제품이 아니라 “고객 요건에 맞춰 이렇게 만들 수 있다”를 보여드리는 예시이며, 해시스크래퍼가 요건에 맞춘 PoC 커스텀 대시보드를 직접 제작해 드립니다.
RAG Data Pipeline
수집·정제·청킹·임베딩·벡터DB 적재를 한 파이프라인으로 운영합니다
128,430
▲ 8.2%
121,902
-5.1%
486,217
완료
470,100
진행
95.2%
진행
10분 전
09:00
처리량 추이
파이프라인 단계
-
1
128,430
수집
완료
-
2
121,902
정제·중복제거
완료
-
3
486,217
청킹
완료
-
4
470,100
임베딩
진행
-
5
462,800
벡터DB 적재
진행
데이터 소스
소스 유형 분포
- 웹문서42%
- PDF24%
- FAQ16%
- 뉴스12%
- 기타6%
품질 점검
| 항목 | 기준 | 결과 | 상태 |
|---|---|---|---|
| 중복률 | < 5% | 4.9% | 통과 |
| 빈 청크 | 0 | 0 | 통과 |
| 임베딩 차원 | 1536 | 1536 | 통과 |
| 평균 토큰 길이 | 512 | 498 | 통과 |
| 벡터DB 적재 | 100% | 95.2% | 진행 |
| 메타데이터 부여 | 100% | 100% | 통과 |
주요 알림
임베딩 작업 진행 중
470,100 / 486,217 (96.7%)
신규 소스 추가
뉴스 채널 3곳 연동
품질 점검 통과
중복률·임베딩 차원 정상
일일 파이프라인 완료
128,430 문서 처리
6대 핵심 지표 · 처리량 추이 · 파이프라인 단계 · 소스 유형 분포 · 품질 점검 · 실시간 알림을 한 화면에서
모델은 붙였는데,
데이터가 막혀 있지 않나요?
최신 데이터가 안 들어온다
모델·LangChain·벡터DB는 올렸는데 정작 답변에 필요한 최신 웹 데이터가 들어오지 않습니다.
운영 인력이 없다
내부 AI팀은 있는데 데이터 수집·적재 파이프라인을 상시 운영할 인력이 없습니다.
파이프라인은 하루아침에 안 만들어진다
안정적인 데이터 수집 파이프라인은 단기 개발로 끝나지 않고 지속적인 운영이 필요합니다.
반복 운영 부담이 크다
수집·정제·중복 제거·품질관리가 매번 반복되는 운영 부담으로 남습니다.
AI팀은 있는데, 데이터 파이프라인 운영 인력이 없다면
RAG의 진짜 경쟁력은 모델이 아니라 데이터입니다. 8년간 운영한 크롤링 인프라로 RAG·검색용 데이터 파이프라인을 운영합니다.
웹 수집
대규모·안정 수집 (로그인·동적페이지 포함)
정제·중복 제거
HTML 정리·중복 제거·구조화
청킹·메타데이터
문서 청킹 + 출처·날짜 메타데이터 부여
임베딩·벡터DB 적재
임베딩 생성 후 벡터DB/검색 인덱스 적재
품질 모니터링·재수집
변경 감지·재수집·품질 점검 운영
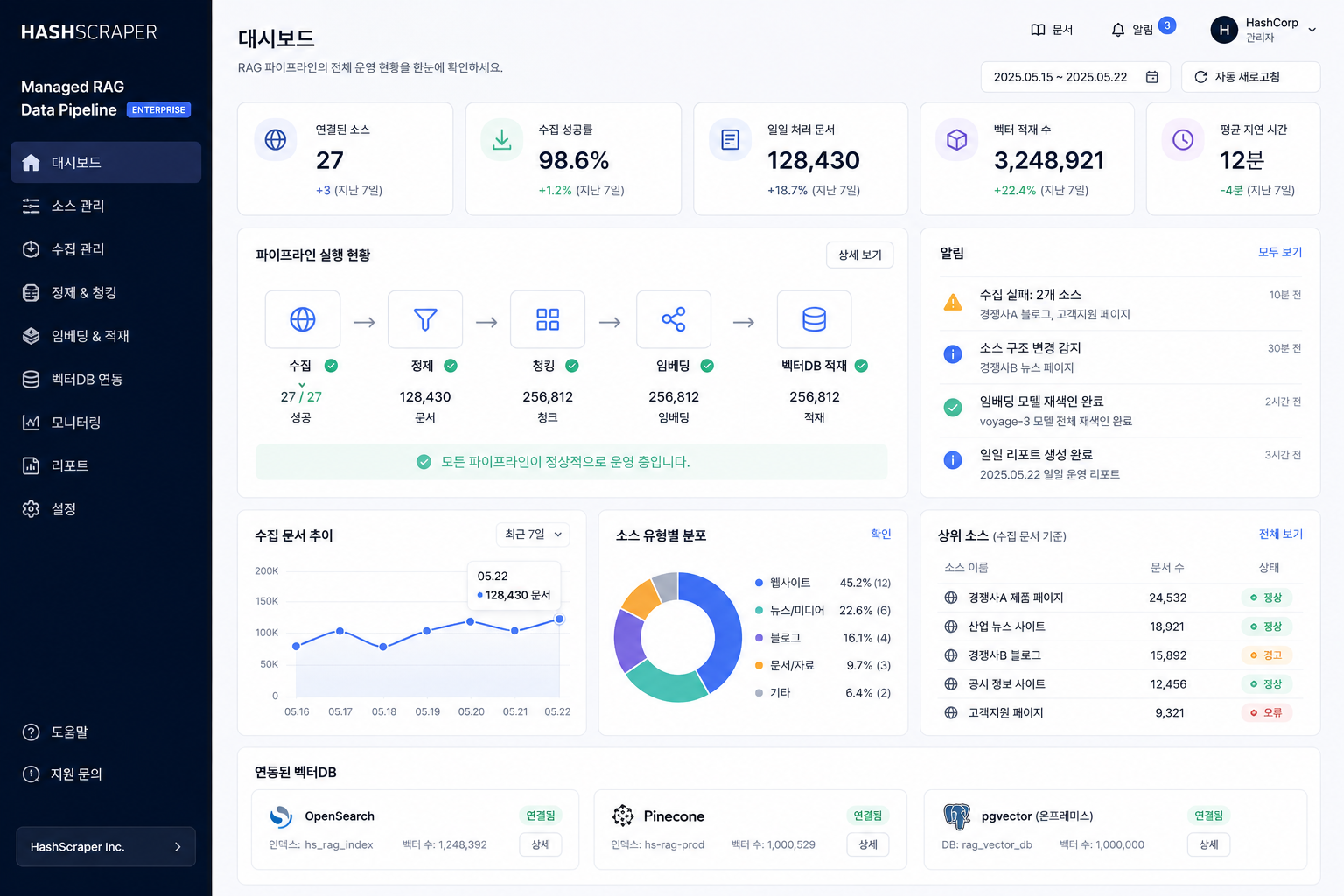
파이프라인 실행 현황 · 수집 문서 추이 · 유형별 문서 · OpenSearch·Pinecone·pgvector 연동을 한 화면에서
LLM은 두뇌, RAG는 기억 장치, 크롤링은 배관입니다.
AI 모델은 API 하나로 바꿀 수 있지만, 안정적인 데이터 수집 파이프라인은 하루아침에 만들어지지 않습니다. 모델 구축이 아니라 데이터 파이프라인 운영을 맡기세요.
바로 연동되는 납품
데이터팀·AI/RAG팀·신사업팀이 내부 파이프라인에 바로 적재할 수 있는 형태로 전달합니다.
모델 구축이 아니라
데이터 파이프라인 운영을 맡깁니다
대규모 안정 수집
로그인·동적페이지 포함 대규모 웹 데이터를 안정적으로 수집합니다.
정제·중복 제거·구조화
HTML 정리, 중복 제거, 노이즈 제거로 학습·검색에 쓸 수 있게 구조화합니다.
청킹·메타데이터
문서를 청킹하고 출처·날짜 등 메타데이터를 부여해 RAG 품질을 높입니다.
임베딩·벡터DB 적재
임베딩을 생성하고 벡터DB/검색 인덱스에 적재합니다.
변경 감지·재수집
원본 변경을 감지해 재수집·재적재로 데이터를 최신 상태로 유지합니다.
품질 모니터링·운영
수집 누락·이상값을 점검하고 장애 대응까지 상시 운영합니다.
팀마다 이렇게 활용합니다
데이터팀
내부 데이터마트에 외부 웹데이터를 정기적으로 수집·적재합니다.
AI/RAG팀
검색·RAG용 데이터셋을 구축하고 벡터DB에 최신 상태로 유지합니다.
신사업팀
새로운 도메인의 데이터를 빠르게 확보해 AI 서비스 검증에 활용합니다.
공공·연구기관
연구·정책 분석에 필요한 공개 웹데이터를 정제된 데이터셋으로 확보합니다.
RAG는 빠르게 표준이 되고 있습니다
19.4억 달러
2025년 기준 기업 RAG 시장 규모로, 빠르게 성장하고 있습니다.
30~60%
기업의 30~60%가 자사 AI 유스케이스에 RAG를 채택하고 있습니다.
AI 모델은 API 하나로 바꿀 수 있지만,
안정적 데이터 파이프라인은 하루아침에 못 만든다.
바로 연동되는 형태로 납품합니다
내부 RAG·검색 파이프라인에 그대로 적재할 수 있는 형태까지 지원합니다
직접 구축할까,
운영을 맡길까?
크롤러는 만드는 것보다 매일 안정적으로 운영하는 것이 어렵습니다
| 비교 항목 | 자체 구축 | 해시스크래퍼 |
|---|---|---|
| 서비스 시작까지 | 개발 2~3개월 | 최대 3일 내 시작 |
| 초기 개발 비용 | 수천만원 | 0원 (월정액 포함) |
| 월 유지보수 부담 | 개발자 인건비 수백만원 | 월정액에 포함 |
| 사이트 구조 변경 | 직접 재개발 필요 | 자동 유지보수 |
| 장애·수집 누락 | 직접 모니터링 | 운영팀이 대응 |
| 데이터 품질 검증 | 직접 구축 | 검증·재시도 기본 포함 |
| 필요 인력 | 크롤링 개발자 채용 | 별도 인력 불필요 |
수집 1회가 아니라 정기 운영·검증·장애 대응·납품까지 포함된 결과물을 구매합니다.
궁금한 점을 확인하세요
벡터DB는 어디로 받을 수 있나요?
pgvector, Pinecone, OpenSearch 등 사용하시는 벡터DB/검색 인덱스에 직접 적재합니다. JSONL 데이터셋·REST API·Webhook 형태로도 납품할 수 있어 내부 파이프라인에 맞춰 전달합니다.
청킹 단위를 조정할 수 있나요?
문서 유형과 검색 품질에 맞춰 청크 크기·중첩(overlap)·분할 기준을 조정합니다. 출처·날짜 등 메타데이터도 함께 부여해 RAG 검색 정확도를 높입니다.
수집 주기는 어떻게 정하나요?
데이터 특성에 따라 일간·주간·월간 또는 변경 감지 기반으로 주기를 설계합니다. 자주 바뀌는 데이터는 변경 감지 후 재수집·재적재까지 운영합니다.
사이트 구조가 바뀌면 어떻게 대응하나요?
원본 사이트 변경을 감지해 수집 로직을 유지보수하고, 수집 누락이 발생하면 재시도·장애 대응으로 복구합니다. 8년간 5,000개 이상 사이트를 운영한 경험을 기반으로 대응합니다.
데이터 품질은 어떻게 검증하나요?
수집 실패 재시도, 중복 제거, 이상값·누락 점검, 적재 검증을 운영 단계에서 수행합니다. 파이프라인 실행 현황과 문서 추이를 운영 대시보드로 모니터링합니다.
대상 사이트와 필요한 항목을
알려주시면 가능 여부를 확인해드립니다
구매 의무 없습니다. 보통 24시간 내 회신하고, 가능하면 샘플 데이터로 먼저 확인해드립니다.
30분 무료 상담 받기
AI·RAG 데이터 파이프라인