우리 업무에 필요한 웹 데이터를
운영 가능한 형태로 설계합니다
지도, 부동산, 공공, 입찰, 연구, AI 학습/RAG용 데이터까지 수집 가능성 진단부터 운영·검증·전송까지 맞춤형으로 제공합니다.
500+ 기업 도입 · 8년+ 운영 경험 · 수집/검증/납품까지 운영
| 분야 | 데이터 예시 |
|---|---|
| 지도/매장 | 업체명·주소·영업시간·리뷰 |
| 부동산 | 매물명·가격·면적 |
| 공공/입찰 | 공고명·기관·기간 |
| AI/RAG | 문서제목·본문·링크 |
맞춤 데이터 운영을 한 화면 대시보드에서 관리
수집 현황·크롤러 상태·데이터 품질·실시간 알림을 한곳에서
아래 화면은 샘플 예시 대시보드입니다. 실제 출시된 제품이 아니라 “고객 요건에 맞춰 이렇게 만들 수 있다”를 보여드리는 예시이며, 해시스크래퍼가 요건에 맞춘 PoC 커스텀 대시보드를 직접 제작해 드립니다.
Custom Data Operations
사이트별 맞춤 크롤러를 설계·운영하고 데이터 품질을 관리합니다
42
▲ 5
1.24M
▲ 18%
99.4%
▲ 0.3%p
12초
안정
3건
▼ 2
10분 전
09:50
일별 수집량
크롤러 현황 TOP 5
-
1
24,500
네이버지도 매장정보
정상09:00
-
2
8,200
공공데이터 입찰공고
정상09:00
-
3
12,800
부동산 매물
재시도10:00
-
4
5,400
내부 ERP 연동
정상08:00
-
5
3,100
채용공고 통합
지연09:00
수집 대상 유형
데이터 품질 분포
- 정상92%
- 보정5%
- 중복제거2%
- 오류1%
수집·납품 현황
| 사이트 | 주기 | 마지막 수집 | 납품 형식 | 상태 |
|---|---|---|---|---|
| 네이버지도 | 매일 | 06.11 09:00 | API | 정상 |
| 공공데이터 | 매일 | 06.11 09:00 | CSV | 정상 |
| 부동산 | 시간별 | 06.11 10:00 | DB | 재시도 |
| 채용공고 | 매일 | 06.11 09:00 | Webhook | 지연 |
| 내부 ERP | 매일 | 06.11 08:00 | API | 정상 |
| 카카오맵 | 매일 | 06.10 09:00 | CSV | 정상 |
주요 알림
사이트 구조 변경 감지
부동산 매물 자동 복구 진행 중
채용공고 수집 지연
대상 사이트 응답 지연
신규 크롤러 배포
카카오맵 리뷰 크롤러
일일 수집 완료
42개 크롤러 정상 가동
6대 핵심 지표 · 일별 수집량 · 크롤러 현황 · 데이터 품질 분포 · 수집·납품 현황 · 실시간 알림을 한 화면에서
필요한 데이터는 명확한데,
안정적으로 운영하기가 어렵습니다
일반 솔루션으로 해결되지 않는다
필요한 사이트, 검색 조건, 상세페이지 구조가 업무마다 다릅니다.
개발보다 운영이 더 어렵다
한 번 만드는 것보다 매일 안정적으로 수집되게 유지하는 것이 어렵습니다.
내부 시스템 연동이 필요하다
CSV 다운로드만으로는 부족하고 API, Webhook, DB 연동이 필요합니다.
수집 가능성과 리스크 판단이 필요하다
공개 범위, 사이트 구조, 수집 주기, 데이터 항목을 먼저 검토해야 합니다.
특수한 웹 데이터도
운영 가능한 구조로 설계합니다
요구사항·가능성 진단
대상 사이트·업무 요구사항을 검토하고 수집 가능성과 운영 리스크를 먼저 판단합니다.
샘플 데이터 수집
본격 운영 전 샘플 데이터를 수집해 항목·품질을 함께 확인합니다.
맞춤 파이프라인 설계
업무에 맞춰 수집 대상·항목·주기를 맞춤 파이프라인으로 설계합니다.
검증·재시도
데이터 검증과 재시도 로직으로 수집 품질을 안정적으로 유지합니다.
API·Webhook·DB·S3 연동
내부 시스템에 바로 들어오도록 API/Webhook/DB/S3 등으로 연동·납품합니다.
유지보수·장애 대응
사이트 구조가 바뀌어도 유지보수와 장애 대응으로 안정적으로 운영합니다.
※ 모든 사이트가 100% 가능한 것은 아닙니다. 대상 사이트 구조·공개 범위·이용 조건을 확인한 뒤 가능 여부와 운영 방식을 안내드리며, 개인정보·비공개 데이터는 수집하지 않습니다.
이런 웹 데이터를 운영합니다
업무·도메인 구조에 맞춰 필요한 분야와 항목을 설계합니다
| 분야 | 데이터 예시 | 활용 예시 |
|---|---|---|
지도/매장 |
업체명, 주소, 영업시간, 리뷰, 카테고리 | 상권 분석, 영업 DB 구축 |
부동산 |
매물명, 가격, 위치, 면적, 중개사 | 시세 모니터링, 매물 DB |
공공/입찰 |
공고명, 기관, 기간, 첨부파일, 상태 | 영업기회 탐지, 정책 모니터링 |
기업/채용 |
회사명, 직무, 지역, 채용공고, 기술스택 | 시장/인재 동향 분석 |
AI/RAG |
문서 제목, 본문, 링크, 업데이트일 | 검색/RAG 데이터셋 구축 |
연구/특수 |
도메인별 공개 데이터 | 리서치/DB 구축 |
※ 공개된 웹 데이터만 수집합니다. 개인정보·비공개 데이터는 수집하지 않으며, 대상 사이트의 구조·공개 범위·이용 조건을 확인한 뒤 가능 여부를 안내드립니다.
AI팀은 있는데, 데이터 파이프라인 운영 인력이 없다면
RAG의 진짜 경쟁력은 모델이 아니라 데이터입니다. 8년간 운영한 크롤링 인프라로 RAG·검색용 데이터 파이프라인을 운영합니다.
웹 수집
대규모·안정 수집 (로그인·동적페이지 포함)
정제·중복 제거
HTML 정리·중복 제거·구조화
청킹·메타데이터
문서 청킹 + 출처·날짜 메타데이터 부여
임베딩·벡터DB 적재
임베딩 생성 후 벡터DB/검색 인덱스 적재
품질 모니터링·재수집
변경 감지·재수집·품질 점검 운영
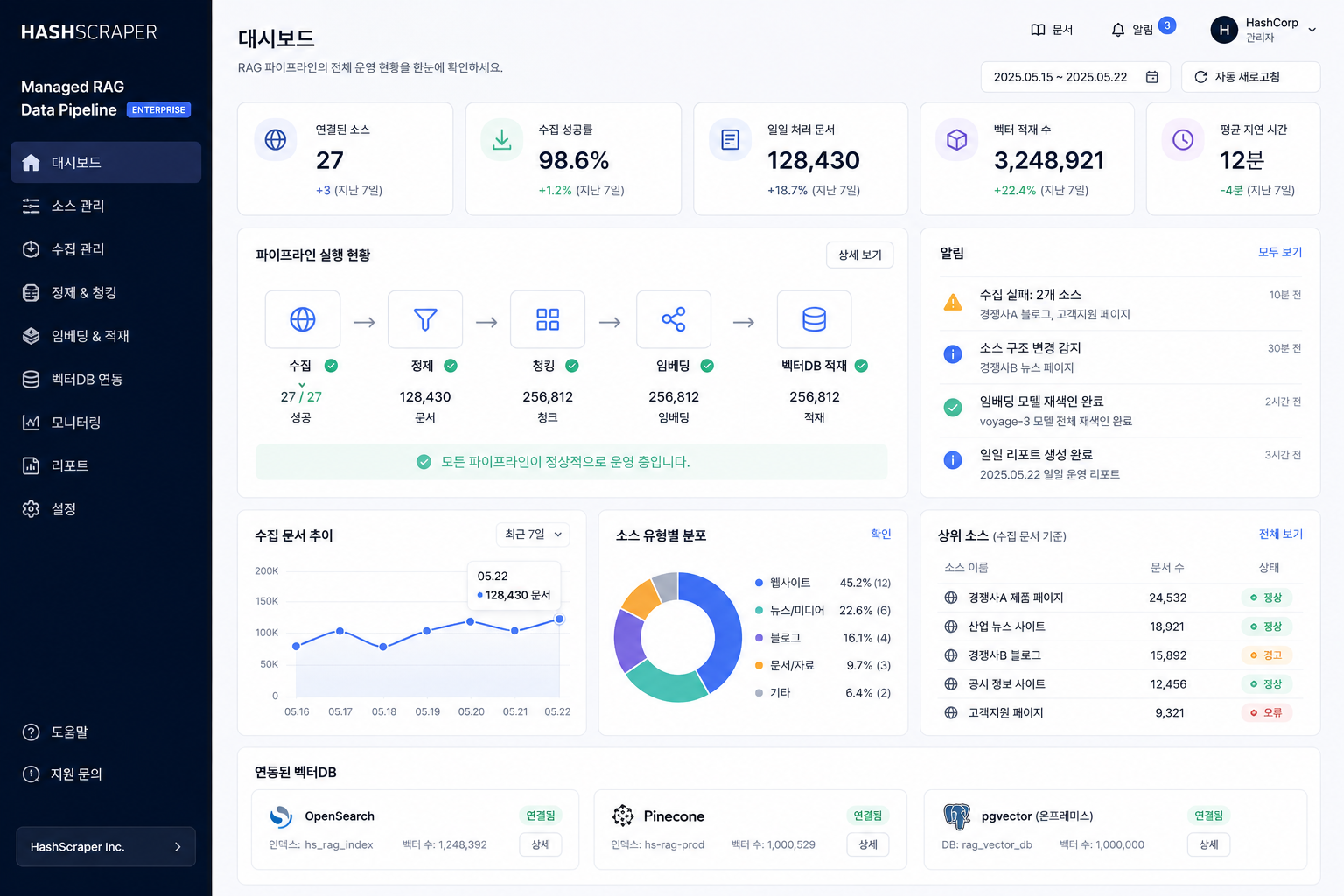
파이프라인 실행 현황 · 수집 문서 추이 · 유형별 문서 · OpenSearch·Pinecone·pgvector 연동을 한 화면에서
LLM은 두뇌, RAG는 기억 장치, 크롤링은 배관입니다.
AI 모델은 API 하나로 바꿀 수 있지만, 안정적인 데이터 수집 파이프라인은 하루아침에 만들어지지 않습니다. 모델 구축이 아니라 데이터 파이프라인 운영을 맡기세요.
바로 연동되는 납품
데이터팀·AI/RAG팀·신사업팀이 내부 파이프라인에 바로 적재할 수 있는 형태로 전달합니다.
데이터를 검사·검증하는 단계까지 운영합니다
단순 수집을 넘어, 모은 데이터에서 위반·오류·허위를 자동으로 찾아냅니다.
상품 상세 광고 컴플라이언스 검사
쇼핑몰 상품 상세페이지의 과대·허위·불법 광고 표현을 자동으로 검사합니다. 이미지 속 텍스트까지 OCR로 읽어, 본문에 적지 않고 이미지로만 넣은 부당 표시도 놓치지 않습니다.
# 상세페이지 이미지 OCR 검사 결과
"국내 유일, 100% 천연, 최고의 효과"
⚠ 절대적 표현·과대광고 의심 (3건)
"먹으면 면역력 강화·질병 예방"
⚠ 일반식품의 의약품 오인 표현 (식약처 표시·광고 가이드)
검사 항목
품질·법무·컴플라이언스팀 · 오픈마켓/플랫폼 운영 · 브랜드 자가점검 · 공공 모니터링
지도·플레이스 데이터 검사
네이버플레이스·카카오맵의 매장 정보(상호·주소·영업시간·전화·리뷰·평점)를 수집하고, 정보의 정확성·누락·변경·허위 여부를 검사합니다.
# 가맹점 정보 정합성 검사
강남점 · 영업시간 불일치 (본사 21시 / 플레이스 22시)
홍대점 · 대표번호 누락
유사상호 허위 등록 의심 2건 탐지
검사 항목
프랜차이즈 본사 · 위치기반 사업 · 영업 DB 구축 · 상권 분석
대상 사이트와 검사 항목을 알려주시면 가능 여부와 운영 방식을 확인해드립니다.
가능성 진단부터 정기 납품까지
요구사항·가능성 진단
대상 사이트 진단
샘플 수집
항목·주기 확정
정기 수집·검증
정기 납품·장애 대응
팀마다 이렇게 활용합니다
데이터팀
내부 데이터마트에 외부 웹 데이터를 정기 적재합니다.
AI팀
RAG·검색용 공개 웹 문서 데이터셋을 구축합니다.
영업팀
지역·업종별 영업 DB를 구축합니다.
공공·연구기관
정책·입찰·공고 데이터를 정기 모니터링합니다.
부동산·지도 사업자
매물·업체·리뷰 데이터를 운영합니다.
원하는 방식으로 납품합니다
내부 시스템에 바로 들어오는 형태까지 지원합니다
복잡한 사이트의 데이터를 내부 시스템에 API로 매일 안정적으로 받고 있습니다. 운영·장애 대응까지 맡겨 부담이 줄었어요.
핀테크 · 데이터팀
API 자동
내부 시스템 적재
직접 구축할까,
운영을 맡길까?
크롤러는 만드는 것보다 매일 안정적으로 운영하는 것이 어렵습니다
| 비교 항목 | 자체 구축 | 해시스크래퍼 |
|---|---|---|
| 서비스 시작까지 | 개발 2~3개월 | 최대 3일 내 시작 |
| 초기 개발 비용 | 수천만원 | 0원 (월정액 포함) |
| 월 유지보수 부담 | 개발자 인건비 수백만원 | 월정액에 포함 |
| 사이트 구조 변경 | 직접 재개발 필요 | 자동 유지보수 |
| 장애·수집 누락 | 직접 모니터링 | 운영팀이 대응 |
| 데이터 품질 검증 | 직접 구축 | 검증·재시도 기본 포함 |
| 필요 인력 | 크롤링 개발자 채용 | 별도 인력 불필요 |
수집 1회가 아니라 정기 운영·검증·장애 대응·납품까지 포함된 결과물을 구매합니다.
궁금한 점을 확인하세요
어떤 사이트든 가능한가요?
모든 사이트가 100% 가능한 것은 아닙니다. 대상 사이트의 구조·공개 범위·이용 조건을 먼저 확인한 뒤 가능 여부와 운영 방식을 안내드립니다.
로그인이나 검색 조건이 필요한 사이트도 가능한가요?
검색 조건·필터가 있는 사이트도 설계할 수 있습니다. 다만 공개 범위와 이용 조건을 확인한 뒤 가능 범위를 안내드리며, 비공개·개인정보성 데이터는 수집하지 않습니다.
API로 바로 받을 수 있나요?
REST API, Webhook, DB 연동, S3 등 내부 시스템에 바로 들어오는 형태로 납품할 수 있습니다. CSV·Google Sheet·리포트 형태도 함께 지원합니다.
샘플 수집 후 계약할 수 있나요?
본격 운영 전 샘플 데이터를 먼저 수집해 항목·품질을 확인하신 뒤 진행 여부를 결정하실 수 있습니다.
개인정보나 비공개 데이터는 어떻게 처리하나요?
공개된 웹 데이터만 수집합니다. 비공개·개인정보성 데이터는 수집하지 않으며, 이용 조건을 확인한 뒤 진행합니다.
전용 서버나 전용 파이프라인도 가능한가요?
수집 규모와 운영 요건에 따라 전용 파이프라인·전용 운영 구성을 제안드립니다. 요구사항을 확인한 뒤 적합한 운영 방식을 안내드립니다.
대상 사이트와 필요한 항목을
알려주시면 가능 여부를 확인해드립니다
구매 의무 없습니다. 보통 24시간 내 회신하고, 가능하면 샘플 데이터로 먼저 확인해드립니다.
30분 무료 상담 받기
맞춤형 웹 데이터 운영